Early Stopping
The main goal of training a neural network is to acquire a model which is able to generalize optimally on new unseen data.
Unfortunately, most of neural network architectures often suffer from overfitting. Overfitting is the effect when the model fits the training data too well. That means, the model is not able to “make sense” of unseen data it receives.

We can also see overfitting as an error which decreases on training data but increases on test data. Ideally, we want a small error while testing.

A typical overfitted graph will look something like in this picture right:

Why is overfitting bad? Well, the central idea of a machine learning algorithm is to capture a dominant trend in the data and be able to recognize this trend on new data again. If we get a graph like the right most in the picture above, that would indicate that the model did not really learn anything but stupidly memorized training data without “understanding” it, hence the test error will be large (or in other words, the network accuracy will be small).
Data Split
First of all, we start off by splitting the whole data into three main subsets: training, validation and test set.
The biggest subset is the training data set. We use it to actually train the model which means we tweak weights and biases by the means of backpropagation. The model learns to “see the world” from this data.
Next the validation data set. This data subset is used to give an unbiased evaluation of a model after fitting it on the training dataset. We also tune model hyperparameters on the validation set.
With the validation set we are allowed to perform evaluation frequently. It works well because the model does not learn from the validation data set. It only “sees” it.
Sometimes the validation set is also referred to as development set.
Finally, the test data set. This subset is used to give an unbiased evaluation of the final model fitted (=trained) on the training data set.
We use the test data set only once when our model is completely trained, meaning we have already applied training and validation sets.

The splittig proportions may vary. As a rule of thumb we can use the following split ratios:
- 70% train, 15% val, 15% test
- 80% train, 10% val, 10% test
- 60% train, 20% val, 20% test
Early Stopping and Validation Error
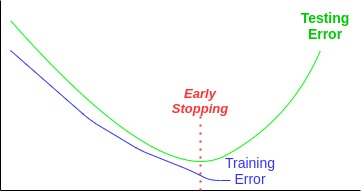
Commonly, a generalization error is approximated by a validation error (=also validation loss). Validation error is the average error computed on a validation set.
Validation can be used to detect when overfitting starts during supervised training.
Overfitting shows itself when the training error is small but the validation error (or, if we use only test/train data split, the test error) is large. We can utilize early stopping to improve the error rate.
.jpeg)
Early Stopping
Early stopping is one of the regularization techniques that helps us to avoid overfitting. With early stopping we monitor and record the validation error. In case the error stops decreasing for some amount of epochs in succession, the training stops.
Let’s see an implementation example with PyTorch.
Look at the class EarlyStopping below:
import numpy as np
import torch
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
"""
Args:
patience (int): How long to wait after last time validation loss improved.
Default: 7
verbose (bool): If True, prints a message for each validation loss improvement.
Default: False
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
Default: 0
path (str): Path for the checkpoint to be saved to.
Default: 'checkpoint.pt'
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score = self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''Saves model when validation loss decrease.'''
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss link to the complete project by Bjarten
The class EarlyStopping tracks the validation error during the model training. A checkpoint of the model is saved each time the validation error decreases:
torch.save(model.state_dict(), self.path) Patience
The patience parameter is important to early stopping. Patience here is the epoch number to wait for an error improvement (=error decrease). If after n epochs there is still no improvement in the error, the training will be terminated.
Let's look at an example from MNIST_Early_Stopping_example.ipynb how to use the EarlyStopping module class.
We import the class from the pytorchtools.py module:
from pytorchtools import EarlyStopping To initialize an early_stopping object, we do:
early_stopping = EarlyStopping(patience=patience, verbose=True) The early_stopping variable checks whether the validation error degraded. In case the error has degraded, it will create a checkpoint of the current model:
early_stopping(valid_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break In the other case it will load the last checkpoint with the best model:
model.load_state_dict(torch.load('checkpoint.pt')) Another way we can think of early stopping is that it gives a smaller neural network that has less capacity but still gives better generalization.
Further Research
For those of you who got interested in the topic, a new gitHub project about Argument Mining Across Heterogeneous Datasets will be linked here in September. It features argument mining implemented with BERT using Huggingface Transformer library and PyTorch, where you can see an example of applying Early Stopping in a more complex environment.
Conclusion
We have learned that stopping a neural network training early before it overfits the training data set can minimize overfitting and improve the neural network generalization capacities.