Word Embeddings
Word embeddings are vector representations of a particular word in a document or a corpus. Embeddings are low-dimensional and dense in their nature, which means they are able to reduce the number of dimensions and still accurately represent categories in the new space.
First of all, let's make some extra terminology clear.
We call two words semantically similar, if they have similar meaning. For example: "happy" - "cheerful", "proceed" - "begin", "flower" - "blossom", etc. and we call two words semantically related, if they have related meanings. Such words don't have to posses a common meaning but they have a relation to some aspect of that meaning. So, these words are not synonymous but are related to each other through some sense which is common. For example: "car" - "highway", "spoon" - "fork", "jump" - "change", etc.
If we describe two words that are semantically related, they probably tend to be written near each other in the context, and they're semantically similar if they tend to be used synonymously. We can also say, that words that appear in the same context, often share the same semantic meaning.

Generally speaking an approach to semantics that is based on the contexts of words in large corpora is called Distributional Semantics.
Representing words as vectors
Look at these sentences: "What a wonderful day" and "What a marvelous day". They actually have the same meaning. If we construct a vocabulary (we just call it V) for these two sentences we get:
V = {What, a, wonderful, marvelous, day}
We could try using one-hot encoding where we take x dimensions for x words and fill in our vectors with 0 in places where the word doesn't occur and only one 1 in a place where the word is that we want to represent.
Let's take our vocabulary V = {What, a, wonderful, marvelous, day} and represent the word "wonderful" as:

The big problem of one hot encoding representations is that all the words are independent of each other and are seen as without any context: therefore without any semantic correlation. This model will not understand that words like "cat" and "dog" belong to the same category "animals/pets". That means that one-hot encoding doesn't set similar words closer to one another in a vector space.
Moreover, the size of such representation grows with the number of words. As a result, it doesn't scale for a larger corpus, e.g. each word vector for a 100 million corpus will be 100 million numerical values with all except one being a zero.
The same problems appear with the Bag-Of-Words Model (BOW) BOW - Bag of Words.
We use the Bag-Of-Words model to create a feature vector (word vector) when the number of features (words) is not known in advance, with the premise that the order of features (words) is not important. Each word in this model is a one-hot vector representation - a sparse vector of the vocabulary size, with a "1" standing for a word in the entry and zeros in all other entries where the word representation is absent. The BOW feature vector is the sum of all one-hot encoded words vectors. This vector has a non-zero value for every word that occurred.

This model receives a list of labeled texts and assigns a word count for each text which is a frequency of a word in a text or document. Then we apply the Bayes' Theorem to the new (unlabeled) text with counts to see the probably which label text belongs to based on that word frequencies.
The negative side is: the BOW Model doesn't consider the semantics of a word. Words like "car" and "automobile" are frequently used in the same context, which is ignored by the model. So, the context is ignored because every word is independent of the occurrence of the other word.
Encodings like one-hot and BOW can still be quite useful and are often used for tasks like email spam classification.
We can take another approach and use different numerical values for our vectors representing words.
It is possible to use multiple dimension, where each dimension is a representation of some meaning. The word's numerical weight on that dimension pictures the word-relatedness to that meaning. Therefore, the word-semantics are embedded across the dimensions of the vector.
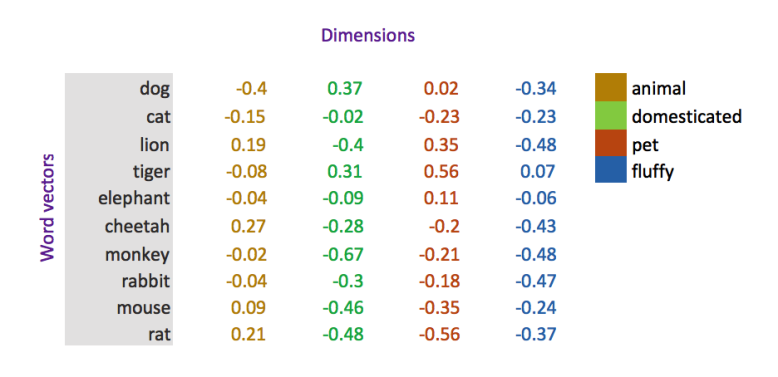
Word vectors are extremely powerful because they enable us to spot similarities across different words by plotting them in a vector space.
A very good question is: how are word vectors generated?
There are some common ways of getting numerical values for vectors which are:
- Counts of word
- Context co-occurrences
- Predictions based on words from context (e.g. with the help of Word2Vec)
The main problem with the one-hot encoding and the BOW models is that they are not able to "learn" as they don't rely on supervision. With embeddings it's different: embeddings could be improved with the help of neural networks. First of all, the embeddings construct their parameters, called weights. Those weights are adjusted to minimize the loss function on some given task. The embedded output vectors are category representations, where similar categories are placed near to one another in the vector space.
One of the most interesting parts about embeddings is that embeddings can be easily used to visualize data such as a relation of words towards one another in a vector space. Because we may have thousands of dimensions, a dimension reduction technique is required to get the dimensions to 2 or 3, so we can actually visualize the data. A popular technique for dimensionality reduction is: t-Distributed Stochastic Neighbor Embedding (t-SNE for short).
Word2Vec
The Word2Vec model takes a text as an input and gives word vectors as an output back.
The first step is: the model builds a vocabulary from the text which is also our training data. After that it learns vector representation of words. The resulting word vectors represents words and can be used as features for many machine learning tasks. The model was originally developed by T.Mikolov in 2013 .
Word2Vec uses a technique often applied in machine learning: train a neural network with a single hidden layer. This neural network should perform some task (Sentiment Analysis, Sequence Tagging, Sequence Prediction, Named Entity Recognition (NER), etc,..). But we will not use that neural network for the task we trained it on. Instead, we want to learn the hidden layer weights. These weights are in fact the "word vectors" that our algorithm is trying to learn.
There are two basic models in Word2Vec: CBOW (Continuous Bag-of-Words) and SG (Skip Gram)
In simple terms, CBOW tries to predict a word from a given context and SG tries to predict context from a given word.
CBOW predicts the most probable word. The problem with CBOW is that it overlooks rare words because they statistical occurrence in a text is small. If you have a context "Yesterday we had a [...] time together!" the CBOW model may suggest you, the most probable words would be: "nice" or "good", but words like "marvelous" will be ignored because they don't appear often overall. So the rare word will be flattened over much more repeated examples of frequent words.
On the other hand Skip Gram predicts the context of a word. Given the word "marvelous" the model will analyze the context in a certain range and give us: "Yesterday we had a [...] time together!"

N-grams
We can encode a word into a vector and inspect it back and forth within a certain range. These ranges are so called "n-grams" and an n-gram is a sequence of n items. There are different versions of n-grams: unigrams, bigrams, trigrams, four-grams or even five-grams. A skip-gram simplifies an n-gram, dropping parts from it.
In the Skip Gram Model this certain range is called "window". The window size is some number meaning if our window size = 2, then the algorithm will look at 2 words behind and 2 words ahead: 4 words in total.
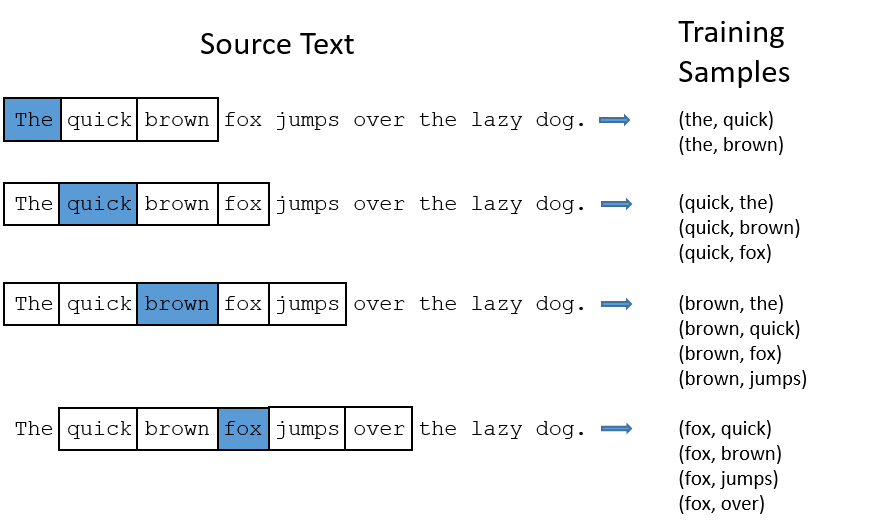
The Skip Gram Model learns statistics from the number of pair occurrences in the context. For example, if we give the model a task: predict 'drove' from the average of the context: ['I', 'on', 'the', 'highway'], the network is presented with the following skip-gram examples: predict 'drove' from 'I', predict 'drove' from 'on', predict 'drove' from 'the', predict 'drove' from 'highway'.
The Model learns from the word-coocurrence statistics. The network is going to gather more examples of e.g. ("bread", "butter") than of ("bread", "metal").
The idea of the Word2Vec Model is easy to understand: it transforms the unlabeled raw data into labeled data. Then the model learns the word representation for an objective.
However there are some downsides to the model in particular to the Skip Gram ...
If you want to know more about Word2Vec, read the part 2 of this article --> LINK PART2
Credits to McCormick, C. Word2Vec Tutorial - The Skip-Gram Model.